
만약 당신이 프로그래밍을 하지 않거나 공학적이지 않은 배경에서 왔다면, 프로그래밍 언어를 배우는 것은 처음에는 조금 두려울 수 있다. 파이썬은 높은 수준의 인터프리터링 언어로 직관적이고 간단한 구문 때문에 상대적으로 배우기 쉽다. 그러나 익힌 내용을 유지하는 것이 어렵고 Excel과 같은 기본 분석 툴에 익숙한 경우 이미 알고 있는 내용과 이러한 학습을 파이썬 판다와 같은 새로운 프로그래밍 언어에 적용하는 것을 쉽게 연결할 수 있습니다.
판다의 데이터 프레임과 그들의 방법은 엑셀 테이블과 매우 유사하게 작동하고 훨씬 더 많은 힘을 더한다. 당신은 판다가 스테로이드에 대한 뛰어난 데이터 질의라고 생각할 수 있습니다. 코드 한 줄로 요약을 생성하고 변수의 특성을 볼 수 있습니다(나중에 자세히 설명). 비록 이것이 코딩 튜토리얼은 아니지만, 저는 여러분이 배운 영역을 활용하여 새롭고 비슷한 기술을 배울 수 있는 방법을 생각해 볼 수 있도록 엑셀과 판다와 유사점을 그려보고 싶습니다.
카글, 커세라, 데이터캠프, dataquest.io, 스택오버플로우 등과 같은 여러 리소스에서 배울 수 있는 파이썬의 기본을 마쳤으면 팬더를 사용하여 엑셀에서 수행한 작업을 수행해야 합니다. 예를 들어, 여러분은 "판다에서 범주 합을 어떻게 수행하나요?" (엑셀에서 SUMIF를 사용하여 수행될 수 있는 것)라고 생각하기 시작해야 합니다. 판다의 기본을 익히면 판다의 선택, 필터링, 방법 체인과 같은 보다 복잡한 조작을 배울 수 있습니다. 판다의 사슬을 묶는 것은 뛰어난 함수에 내포된 것과 매우 유사하다고 생각할 수 있지만, 판다는 한 번에 데이터를 완전히 변환하는 능력이 훨씬 더 뛰어나며, 그렇지 않으면 여러 기능을 사용하고 보충 데이터를 작성할 수 있다. 또한 Excel에서는 원하는 결과를 얻기 위해 도우미 열과 추가 데이터 프레임/테이블을 만들어야 합니다.
이 섹션에서는 엑셀에서 팬더까지 어떻게 형태 연결을 시작할 수 있는지에 대한 간단한 예를 제시합니다.
# generating some random data
#importing libraries
import pandas as pd
import numpy as np
np.random.seed(1) # will ensure you get the same number every time you run this code
data = np.random.randint(0,100,size=(5, 4)) # creating some random data to pull into a pandas data frame
df = pd.DataFrame(data, columns = ['C1','C2','C3','C4']) # creating a pandas dataframe which could be thought as equivalent to an excel table
df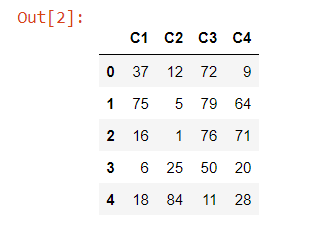
df.sum(axis=0) #equivalent to =SUM(of values along each column) in excel, if axis = 1 it will give sum of values in each row - horizontal sum

#selecting a single column in a dataframe
df['C1'] #selecting first column
#selecting a row
df.iloc[0,:] #selecting first row, pandas index starts from 0
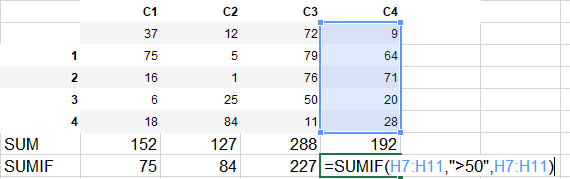
#provide sum of rows after filtering the values >50 in each column
df[df>50].sum() #equivalent to =SUMIF(range=C1 column,criteria = '>50',sum_range = C1 column) and then dragging to all other columns
이제 모든 데이터에 대한 기술 통계량을 만들려면 .describe() 방법을 사용하여 판다의 코드 한 줄에서 이 작업을 수행합니다. 이 방법은 엑셀에서 다른 공식을 구성해야 합니다.
df.describe()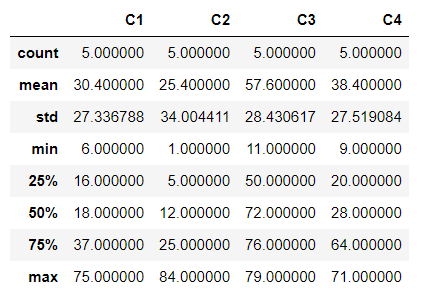
요약 그래프, 범주형 정보 및 쉽게 내보낼 수 있는 대화형 html 보고서를 생성하는 판다 프로파일링을 사용하여 요약 통계 및 탐색 데이터 분석(EDA)을 더욱 확장할 수 있습니다.
요약:.
제가 보여드린 것은 엑셀에서의 기본적인 기능과 판다에서의 그에 상응하는 방법들입니다. 비결은 하나의 도구/언어로 습득한 지식을 사용하여 새로운 프로그래밍 언어를 배우는 것입니다. 여기 몇 가지 중요한 테이크아웃이 있습니다.
- 엑셀에서 분석한 간단한 데이터 집합을 취합하거나 생성하세요.
- pd.read_excel(
filename)을 사용하여 원시 데이터 집합을 Excel에서 Panda로 내보냅니다. - 판다에서 모든 계산을 다시 만들어 보십시오. Google과 스택 오버플로우는 가장 친한 친구입니다.
- 판다에게 더 많은 방법을 사용하여 EDA를 확장하십시오.
- 편안해지면 팬더에서 방법 체인으로 진행합니다.
마지막으로 전환에 도움이 된 리소스를 공유하고자 합니다.
- LinkedIn 학습에서 파이썬을 사용한 데이터 분석(위의 방법을 사용해 본 후)
- Datacamp가 판다를 사용한 데이터 조작
- Frank Andrade의 "Excel에서 Python으로 이동하기 위한 완전하면서도 간단한 가이드"는 코드와 튜토리얼을 통해 Excel과 판다의 또 다른 아름다운 컴파일 및 비교입니다.
- 아디아만 키르티의 판다 체인의 불합리한 효과
제 다른 기사는 여기서 읽으실 수 있습니다.
성공적인 데이터 과학자가 되기 위해 math/stat가 필요하십니까?
EEG 데이터가 주요 우울 장애(MDD)의 임상 진단에 도움이 될 수 있습니까?
저를 팔로우하셔서 제가 그런 기사를 더 많이 쓸 수 있도록 도와주시고 격려해 주세요.
즐거운 독서!
'프로그래밍' 카테고리의 다른 글
| 소프트웨어 개발자로서 돈을 버는 6가지 방법 (0) | 2022.01.04 |
|---|---|
| 개발자들에게 악몽을 가져다주는 호러 코딩! (0) | 2022.01.04 |
| 청정 코드 및 모범 코딩 관행을 달성하기 위한 가이드 (0) | 2022.01.04 |
| 2022년에 배울 최고의 프로그래밍 언어 (0) | 2022.01.04 |
| Azure Serverless 함수 및 Node.js를 사용하여 REST API 생성 (0) | 2022.01.04 |




댓글