
제가 첫 번째 글을 쓸 때, 저는 단지 NFT 이미지 생성 과정을 탐색하고 있었습니다. 자세히 알아보니 단순히 이미지를 생성하는 것만이 아니라 메타데이터를 생성하고, 이미지를 클라우드에 저장하는 것도 가능하다는 것을 알게 되었습니다. 이 기사는 첫 번째 기사의 개선된 버전이라고 생각하시면 됩니다.
이 코드는 이전 코드보다 몇 가지 개선된 점이 있습니다. 주요 내용은 다음과 같습니다.
- 사용자는 원하는 만큼 레이어를 추가할 수 있으며, 코드에서 레이어의 이름만 지정하면 된다.
- 각 계층의 변형 수는 동일할 필요가 없으며, 코드는 각 폴더의 파일 목록을 로드하여 계층 사용을 나타낸다.
- 이 코드는 생성된 이미지의 메타데이터를 포함하는 .json 파일도 생성합니다.
다시 한 번 말하지만, 나는 전문 프로그래머가 아니며 내 코드는 작업을 수행하는 가장 좋은 방법이 아닐 것이다. 하지만 이봐, 그것은 효과가 있다!
디렉토리 구조:
다음 이미지는 디렉토리 구조를 보여줍니다.
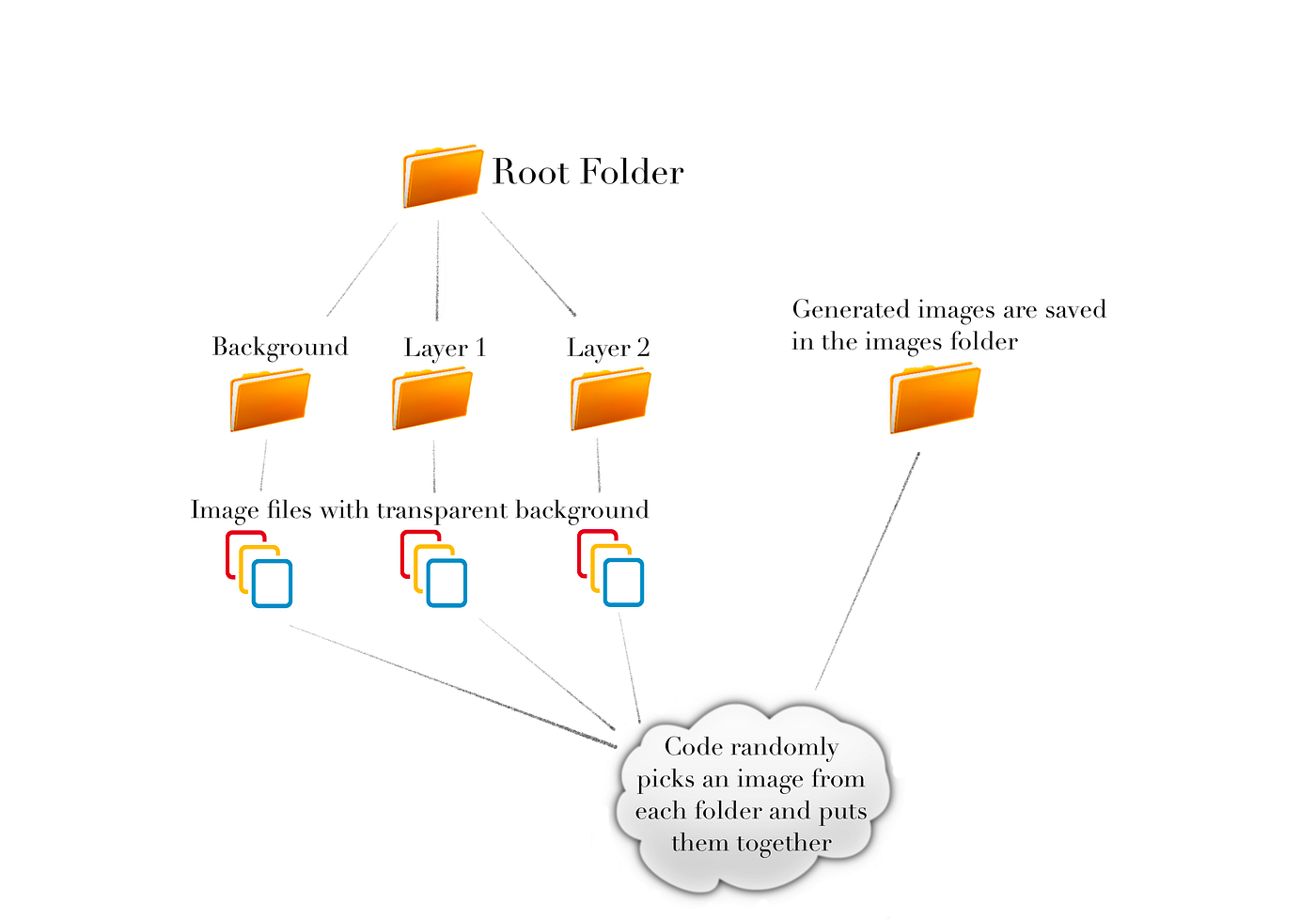
루트 폴더에는 각각 계층을 나타내는 하위 폴더가 포함되어 있습니다. 레이어를 나타내는 각 하위 폴더에는 레이어를 선택하고 병합하려는 순서대로 번호가 매겨져야 합니다. 그래서 배경인 이미지의 가장 낮은 층은 이름 "1", 다음 층 "2" 등이 될 것입니다. 5개의 레이어로 구성된 이미지에서 배경은 1이고 가장 위에 있는 레이어는 5가 됩니다.
각 도면층 하위 폴더에는 해당 도면층의 각 변형을 나타내는 이미지 파일이 포함됩니다. 업데이트된 코드가 파일 이름을 불러오기 때문에 번호를 매길 필요가 없습니다. 그러나 생성된 이미지 파일의 메타데이터에 사용되므로 각 파일의 이름을 적절하게 지정해야 합니다.
클라우드에 이미지 저장:
당신의 NFT 컬렉션의 모든 이미지는 어딘가에 저장되어야 합니다. 원하는 곳에 저장하도록 선택할 수 있지만 언제든지 사진에 액세스할 수 있도록 신뢰할 수 있는 스토리지여야 합니다. 인기 있는 옵션은 피냐타입니다. Pinata는 행성 간 파일 시스템이라고 하는 피어 투 피어 파일 시스템에 데이터를 저장합니다. 피냐타는 꽤 직설적이에요. 최대 1GB까지 무료 스토리지로 등록할 수 있습니다. 로그인한 후 폴더를 업로드합니다. 테스트 파일이 있는 폴더라면 어디든 좋습니다. 이 단계에서는 메타데이터 파일에서 사용할 수 있는 URL 주소를 가져옵니다. 폴더를 업로드한 후 홈 페이지로 돌아가면 폴더 이름이 표시됩니다. 그 옆에는 알파벳과 숫자의 긴 순서인 CID가 보이실 겁니다. 그것을 복사하여 쉽게 접근할 수 있는 위치에 저장하세요. 우리의 코드에 필요할 것입니다.
매개 변수 설정:
몇 가지 매개 변수를 정의해 보겠습니다.
#Name of your project, using test for now.
project = ‘test’
#The CID of the folder on Pinata.
url = ‘QtgdsX3fsfT45fsggrd’
#The local folder which will have the layers' subfolders.
folder = ‘layers’
#The number of images you want to generate.
count = ‘100’
#List containing the names of the layers, in the sequence you want
#the layers to be picked by the code and merged.
layers_names = [“background”, “face”, “shirt”, “accessory”]생성할 수 있는 이미지의 총 수는 각 계층의 하위 폴더에 있는 파일 수를 곱하여 계산할 수 있습니다. 4개의 레이어가 있고 각 레이어가 파일로 표현되는 4개의 변형을 가진다고 가정하자. 가능한 고유 이미지의 총 수는 다음과 같습니다.
4x4x4x4=256레이어를 더 추가하면 숫자가 기하급수적으로 증가합니다. 그러나 테스트의 경우 시간이 많이 걸리기 때문에 100 또는 10으로 설정할 수 있으므로 그렇게 많은 이미지를 생성하지 않는 것이 좋습니다.
필요한 라이브러리 가져오기:
import random
import os
from itertools import product
from PIL import Image가능한 모든 변형 파일 조합 생성:
이제 폴더 매개 변수로 지정된 폴더의 각 하위 폴더에 파일 목록을 로드하겠습니다. 그런 다음 가능한 모든 조합에서 이들을 결합하여 각 층의 변형 가능한 조합을 포함하는 튜플 목록을 생성할 것이다. 이 작업은 코드 한 줄로 수행할 수 있습니다.
combinations = list(product(*[os.listdir(f'{folder}/{x}') for x in os.listdir(folder)]))이 목록의 각 항목은 각 레이어의 가능한 변형 조합을 나타냅니다. 우리는 파일명을 기준으로 파일을 로드하고 병합하는 데 사용할 것입니다. 끝까지 진행하지 않고 이미지 수를 더 적은 수로 제한한 경우 이 목록을 섞는 것이 좋습니다.
random.shuffle(combinations)이미지 및 메타데이터 생성:
다음 코드는 조합 목록의 각 조합을 반복하여 각 계층 폴더에서 이미지를 로드하여 하나의 이미지로 병합한 다음 해당 이미지에 대한 메타데이터를 생성하고 저장합니다.
c=0
metadata={}
for combination in combinations:
if c != count:
if len(combination)>2:
comp = image.alpha_composite(image.open(f'{folder}/1/{combination[1]}').convert('RGBA'),
image.open(f'{folder}/2/{combination[2]}').convert('RGBA'))
n=3
for item in combination[2:]:
if combination.index(item)!=-1:
comp = Image.alpha_composite(comp,
image.open(f'{folder}/{n}/{item}').convert('RGBA'))
n+=1
rgb_im = comp.convert('RGB')
file_name = str(combinations.index(combination)) + ".png"
rgb_im.save("./images/" + file_name)
metadata['image']=f'{image_url}/{file_name}'
metadata['tokenId']=str(combinations.index(combination))
metadata['name']=project+' '+str(combinations.index(combination))
metadata['attributes']=[]
for item in layers_names:
metadata['attributes'].append({item:combination[layers_names.index(item)][:-4]})
with open(f"./metadata/{str(combinations.index(combination))}.json", "w") as outfile:
json.dump(metadata, outfile, indent=4)
c+=1
else:
break변수 "c"는 생성된 파일의 수를 기록하고 각 반복이 끝날 때마다 업데이트됩니다. "결합" 목록의 각 항목에 대해 코드는 먼저 "c" 값을 검사하며, "count" 변수와 같지 않으면 루프를 깨트릴 것이다.
처음 두 레이어에 대해서는 경로를 하드 코딩해야 했습니다. 더 나은 방법이 있을 거라고 확신하지만, 이해할 수 없었습니다. 처음 두 개의 레이어 외에 다른 레이어가 하나씩 로드되어 이전에 병합된 레이어와 병합됩니다.
"결합" 목록에 있는 각 항목의 색인은 이미지 파일과 json 파일의 파일 이름으로 사용됩니다. 우리는 메타데이터를 위해 "layers_names" 목록이 필요합니다. 목록의 각 항목은 이미지의 속성을 나타내며 값은 해당 계층에서 해당 변동을 나타내는 파일의 파일 이름입니다. 따라서 모든 계층의 폴더에 있는 각 변형은 메타데이터에 표시될 때 적절하게 이름이 지정되어야 합니다. 이미지는 "이미지" 폴더에 저장되고 메타데이터 파일은 "메타데이터" 폴더에 저장됩니다.
코드는 적절한 들여쓰기와 함께 표시되지 않을 가능성이 높으므로 주피터 노트북을 확인해 보십시오. 앞서 언급했듯이, 제 코드는 유치할 수 있지만 저는 배우러 온 것이고 당신의 피드백은 확실히 제 향상에 도움이 될 것입니다. 여기까지 읽어주셔서 감사합니다. 프로젝트를 진행하면서 배운 것을 공유하겠습니다.
'프로그래밍' 카테고리의 다른 글
| C — SS 블로그의 배열을 사용한 스택 구현 (0) | 2021.12.30 |
|---|---|
| (도커) docker.io mysql에 대한 오류 [내부] 로드 메타데이터 (0) | 2021.12.30 |
| 당신의 넥스트JS 웹사이트를 2022년에 더욱 친근하게 만드세요. 자동 업데이트 사이트맵을 쉽게 추가할 수 있습니다. (0) | 2021.12.30 |
| 책임 연쇄 설계 패턴 (0) | 2021.12.30 |
| Google Foobar Challenge의 팁과 힌트 (0) | 2021.12.30 |



댓글